
Hello, this is Comcx (or Ireina)1. I'm a programmer writing Rust, C/C++, Java, Go and Haskell.
Ex falso quodlibet
🚧 for underwork(unfinished) state
Blog
categories
programming
rust
math
workout
linguistics
anime
work
game
2024/12
2024/10
2024/09
2024/08
- 🚧 Unravel Tokio's
CurrentThreadruntime - Why the color of a function is our friend
- 🚧 基于省略规则的轻量级英语语法系统
- Golang does have sum types, however...
- 🚧 Rewatch Code Geass
- Another view of Rust's lifetime
- The two sides of programming languages
- My programming key bindings
- Polymorphism in Rust
Relaxedordering and visibility- Golang is terrible as a general purpose language
Digimon exhibition
@tag(anime)

今天看到了数码宝贝的展览,就顺道去参观了一下;整体办的内容有限(甚至有点简陋,电话亭居然不能用!),不过确实勾起了不少回忆。 似乎基本主要是90年代末左右的人会关注digimon,大概是因为那段时间电视上有播放吧。
整个展厅是顺着动画的剧情时间轴去布置的,每个展厅代表一个动画的篇章:
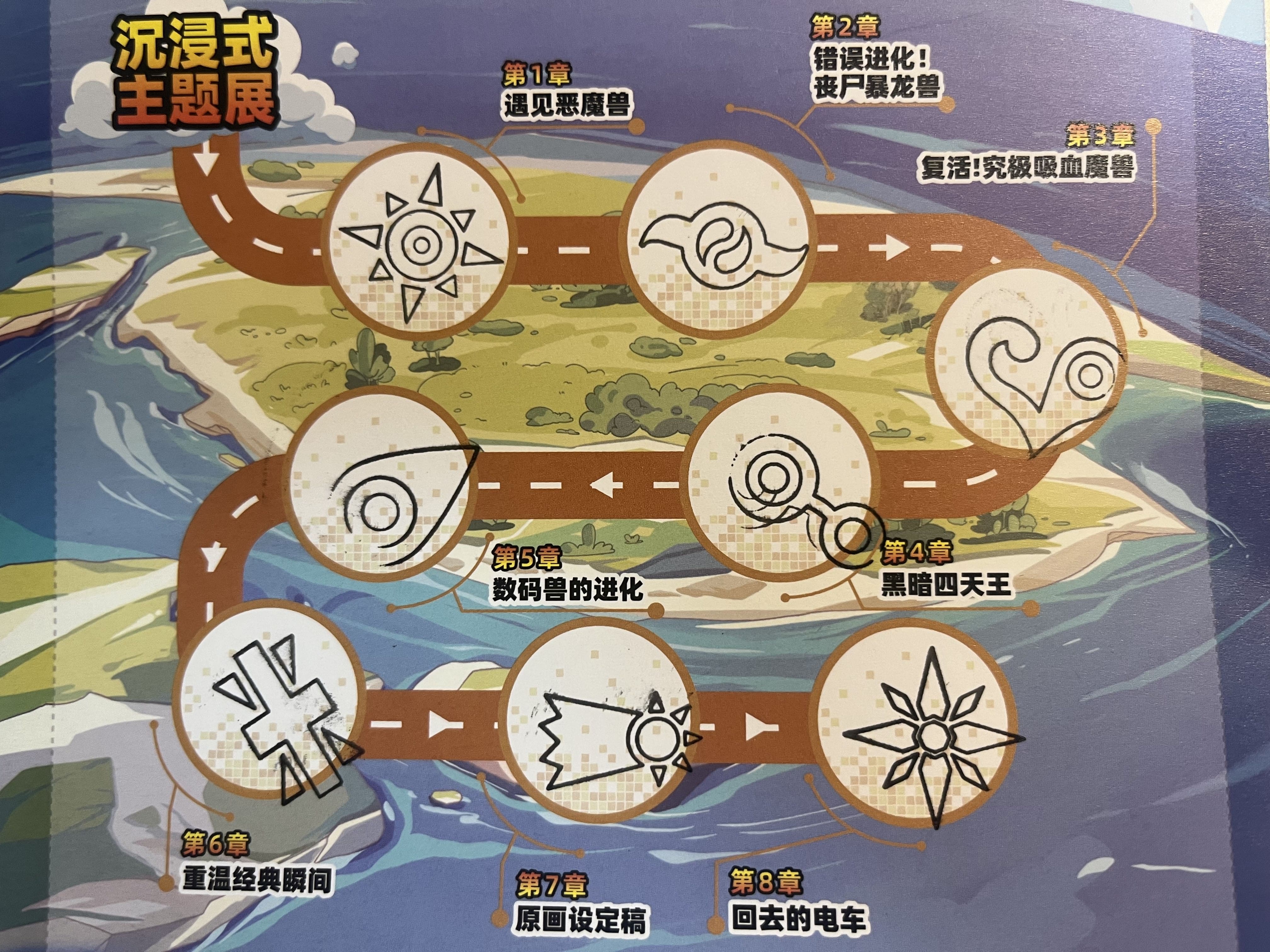
一开始看到的是成长期的进化画面(巴鲁兽卖萌ing)
 还记得幼年期第一期进化的场景(虽然在悬崖边掉到了河里)。
还记得幼年期第一期进化的场景(虽然在悬崖边掉到了河里)。
在理解了数码宝贝世界基本的世界观之后,我们的小队很快遇到了恶魔兽。小时候觉得恶魔兽引诱孩子们进别墅的情节非常经典,其中有幅画似乎在暗示天使与恶魔同在。

接下来我们就遇到了悟空兽,除了悟空兽的出场BGM之外,我印象最深的还是暴龙兽的错误进化,这也让太一第一次开始思考鲁莽与勇气之间的区别。

除了恶魔,西方另一个经典的形象就是吸血鬼,所以接下来我们又遇到了吸血魔兽,某种意义上算是恶魔兽的加强版,也是这一段剧情了拓展了数码宝贝的世界观,发现数码世界是与现实世界相连的(这一设定十分超前,其中也深化了动画的主题,引入了家庭、父母、同龄人、虚拟与现实之间的关系探讨):

可惜没有看到南瓜兽和矿石兽的万圣节之旅,我永远也忘不了这个情节。
正当我们以为打败吸血魔兽就可以恢复虚拟与现实之间的秩序之时,又出现了黑暗四天王,其中我印象最深的还是小丑皇,最绝望的时刻,只剩下希望:


最后的最后,实际上最终的boss是所有不幸的digimon的怨念,没有人为他们伸张权利,一切都是优胜劣汰的自然法则。到这里,伴着回到现实的列车和butterfly,我和主角小队们一同回到了现实。

临走的时候,发现还有战斗暴龙兽的雕像

最后我买了一个盲盒,居然真的抽中了我编程的启蒙大佬光子郎:

Bash may swallow signals
@tag(programming)
Recently I encountered a confusing bug:
A simple
eprintln!in Rust may cause panic!
That sounds weird, right?
Let's check the eprintln!'s doc:
Prints to the standard error, with a newline.
Equivalent to the
println!macro, except that output goes toio::stderrinstead ofio::stdout. Seeprintln!for example usage.Use
eprintln!only for error and progress messages. Useprintln!instead for the primary output of your program.See the formatting documentation in
std::fmtfor details of the macro argument syntax.Panics
Panics if writing to
io::stderrfails.Writing to non-blocking stderr can cause an error, which will lead this macro to panic.
Examples
eprintln!("Error: Could not complete task");
Therefore, at least we can conclude that print will only panic when the stderr cannot be written, but how?
Redirected stderr
I checked the original stderr and It's normal. But quickly I noticed that the rust program's stderr was been redirected to another process's input.
Now the problem seems to be clear:
The process which redireced Rust's program's stderr exits, then
eprintln!writes to broken pipe and panic!
But why? Why still write to stderr when something is broken?
Bash launched bash
I noticed that the launch shell did not directly exec Rust program.
In stead, it call bash on another bash script which exec the real program.
For a minimal example:
# launch.sh
bash run.sh
# run.sh
exec program
When we run the launch.sh:
bash launch.sh
We create 2 processed: bash lanuch.sh and program.
It seems still fine. But if you try to kill the bash process, you can observe that, although the bash process is killed, the program process is still alive!
BASH SWALLOWS SIGNALS!
Now we completely unravel the reason:
When the pod try to exit and kill process, it failed to kill the real process and leave it writing to broken pipes which leads to panic and coredumps.
Rusty docker setting
@tag(programming)
Recently I'm learning debugging and profiling tools of Rust on Linux. I utilize docker to build a debian container and install various kinds of tools(e.g., LLDB, perf). However, to use LLDB in docker container, there're some notices which one may need to care.
LLDB python3 lib path problem
I install LLDB ion the official Rust image via:
apt-get install lldb python3-lldb
But when I typed rust-lldb, I encountered the following error messages:
ModuleNotFoundError: No module named ‘lldb.embedded_interpreter’ · Issue #55575 · llvm/llvm-project;
After quite some googling, I found this script useful:
ln -s /usr/lib/llvm-14/lib/python3.11/dist-packages/lldb/* /usr/lib/python3/dist-packages/lldb/
Still, the version of python may vary on different lldb versions. Replace the actual version number if necessary.
Container addtional options
When I thought "I have fixed the python3 problem and here we go!", another problem arises. I just cannot use LLDB commands!
It turns out that I have to include some addtional options to enable debugging:
docker run -dit --cap-add=SYS_PTRACE --security-opt seccomp=unconfined rust
Now LLDB is ready for debugging rust programs!
Inside Tokio's task_local!
@tag(programming)
Recently I'm curious about Tokio runtime's task_local and LocalKey.
How can this macro ensure task-level global variable?
task_local! is based on thread_local!
Let's unravel task_local the macro's definition:
#![allow(unused)] fn main() { #[macro_export] #[cfg_attr(docsrs, doc(cfg(feature = "rt")))] macro_rules! task_local { // empty (base case for the recursion) () => {}; ($(#[$attr:meta])* $vis:vis static $name:ident: $t:ty; $($rest:tt)*) => { $crate::__task_local_inner!($(#[$attr])* $vis $name, $t); $crate::task_local!($($rest)*); }; ($(#[$attr:meta])* $vis:vis static $name:ident: $t:ty) => { $crate::__task_local_inner!($(#[$attr])* $vis $name, $t); } } #[doc(hidden)] #[macro_export] macro_rules! __task_local_inner { ($(#[$attr:meta])* $vis:vis $name:ident, $t:ty) => { $(#[$attr])* $vis static $name: $crate::task::LocalKey<$t> = { std::thread_local! { static __KEY: std::cell::RefCell<Option<$t>> = const { std::cell::RefCell::new(None) }; } $crate::task::LocalKey { inner: __KEY } }; }; } }
where we can clearly conclude that task_local! is based on thread_local!.
However, threads are reused by multiple different tasks asynchronously.
If task 1 yields, the thread may be scheduled to another task 2.
When task 1 is ready to run again, it may select another thread 2 to poll.
Therefore, thread_local values may be overwritten or lost.
Swap!
So, how does task_local ensure thread_local values not be overwritten or lost?
The secret is under the implementation of Future for task::LocalKey's wrapper.
Firstly, to use a LocalKey, one need to scope it and produce a TaskLocalFuture<T, F>
which binds T and the corresponding task's future F:
#![allow(unused)] fn main() { impl<T> LocalKey<T> { pub fn scope<F>(&'static self, value: T, f: F) -> TaskLocalFuture<T, F> where F: Future, { TaskLocalFuture { local: self, slot: Some(value), future: Some(f), _pinned: PhantomPinned, } } fn scope_inner<F, R>(&'static self, slot: &mut Option<T>, f: F) -> Result<R, ScopeInnerErr> where F: FnOnce() -> R, { struct Guard<'a, T: 'static> { local: &'static LocalKey<T>, slot: &'a mut Option<T>, } impl<'a, T: 'static> Drop for Guard<'a, T> { fn drop(&mut self) { // This should not panic. // // We know that the RefCell was not borrowed before the call to // `scope_inner`, so the only way for this to panic is if the // closure has created but not destroyed a RefCell guard. // However, we never give user-code access to the guards, so // there's no way for user-code to forget to destroy a guard. // // The call to `with` also should not panic, since the // thread-local wasn't destroyed when we first called // `scope_inner`, and it shouldn't have gotten destroyed since // then. self.local.inner.with(|inner| { let mut ref_mut = inner.borrow_mut(); mem::swap(self.slot, &mut *ref_mut); }); } } self.inner.try_with(|inner| { inner .try_borrow_mut() .map(|mut ref_mut| mem::swap(slot, &mut *ref_mut)) })??; let guard = Guard { local: self, slot }; let res = f(); drop(guard); Ok(res) } } }
The value T is initialized when polled the first time.
The future impl is as follows:
#![allow(unused)] fn main() { impl<T: 'static, F: Future> Future for TaskLocalFuture<T, F> { type Output = F::Output; #[track_caller] fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output> { let this = self.project(); let mut future_opt = this.future; let res = this .local .scope_inner(this.slot, || match future_opt.as_mut().as_pin_mut() { Some(fut) => { let res = fut.poll(cx); if res.is_ready() { future_opt.set(None); } Some(res) } None => None, }); match res { Ok(Some(res)) => res, Ok(None) => panic!("`TaskLocalFuture` polled after completion"), Err(err) => err.panic(), } } } }
Whenever the future is used to poll again, it just SWAP the global thread_local slot and the value inside TaskLocalFuture and SWAP back when finished.
As easy as pie ;)
Unravel Tokio's CurrentThread runtime
@tag(programming)
Tokio provides nice async runtimes and async utilities.
I'm curious on its implemention of runtimes. Let's see its CurrentThread runtime first!
Overview
Spawn
Worker
Why the color of a function is our friend
@tag(programming)
When talking about 'stackful coroutine vs stackless coroutine',
Some people claims that stackless coroutine's async color is infectious.
Once a function awaits for async operations, it's async too.
Therefore stackful coroutine is better for managing complex coding.
This point is TOTALLY WRONG.
All colors, not only async, are all our friends! They can help us manage complex structures of program.
Stackful goroutine without color is not that good
Suppose a Golang function with the following signature:
func handle()
and now a new programmer Ireina joins the project and simply use the function in a blocking function logic:
func logic() {
handle()
}
If function handle is a non-blocking call, then everything is ok.
However, if handle is a blocking call or can consume much time and Ireina didn't notice this,
logic may block the whole program. Even if logic cause no serious problem, another new programmer may create another function logic2 calling logic, and logic3 calling logic2, which wil eventually cause blocking problem.
Functions without color still need better document or comment to tell the caller how to use it and how to choose proper context to use it. Even worse, if some inner function may panic, it will destroy the whole calling chain!
How about channels as return type?
func handle() <-chan string
This way is much much better! but in fact it is marking async effect now! This is not about stackful coroutines, it's just about abstraction and constraints.
Async should be marked and controled
Now suppose handle is marked as async in Rust:
#![allow(unused)] fn main() { async fn handle(); // or fn handle() -> impl Future<Output=()> + Send; }
Now Ireina only has 2 options of using it:
- Explicitly use a runtime to block on it until finished.
- Mark
logicasasynctoo.
She can never simply blocking on it without noticing.
Colors can serve as a tool which indicate many side-effects a function can cause. Also, colors within a proper type system can prevent many potential bugs and performance issue.
Color of effects
Beside async, there also exists many kinds of effects, such as error handling, IO, optional, dependency injection, etc. We can even compose these effects or even abstract over it to support various kinds of effects without changing code!
Embrace colors and effects!
基于省略规则的轻量级英语语法系统
@tag(linguistics)
对于单纯的语言使用者而言,一门自然语言的语法其实并不是很重要,只有语言学者才会在意并尝试进行系统化。 但是在缺失语言环境的条件下,我们不得不了解语法来帮助我们快速联系并建立直觉和语感。 传统的英语语法往往会分门别类,对许多细节的严谨性也会导致最终总结的规则较为复杂;我认为其实自然语言并非类似数学或者编程语言那样的形式化语言,自然语言更接近一种符合直觉的,便于沟通而不断迭代演进的结果。因而我想阐述一种非常简化的基于省略系统的语法系统,帮助自己快速抓住英语语法中的直觉和思维习惯。
本文会慢慢完善和补全,目前只是大概整理下思路
基本句式
传统语法倾向于至少将英语句式分为四种:主谓宾、主系表、主谓宾宾和主谓宾补。我认为其实只需要前两种就够了,后两种只是从句省略之后的结果。 由于从句省略会在后文集中阐述,这里我们简单记住英语主要有两种句式就可以了:
| 结构 | 解释 |
|---|---|
| S + V + O | 主谓宾 |
| S + V + C | 主系表(补语) |
其中,主谓宾中的宾语可能省略,因为动词本身就足够表达含义了。
动词变形
英语与汉语相比,有几个不一样的地方:
- 需要专门指定量词,比如one, a, the, 以及动词后加
s。 - 需要将动词变形俩表达时间、语气、可能性等额外的信息。
- 对人称的表示存在宾格,人称会随出现的位置而变形。
这里最重要的是第二点,这一点引出了英语语法的无数表达方式,即动状词(动词变形)。 作为谓语的动词部分,会由于不同使用的情景发生变化(单复数、时间、语气、不确定性,etc)。 举个例子:
All men are created equal.
传统的英语语法大概会告诉我们:are created作为谓语存在。另外我们还发现create这个词变成了过去分词,配合be动词来表达被动的含义。
这种动词的变化就是一种动词变形。这里我觉得其实将句型看作S+V+C更好一些,created是动词变形然后变成了一种形容词,有被动的含义。
这类动词变形主要包括:过去分词、现在分词、单复数。其中现在分词和动名词很像,只不过动名词可以当作名词或名词短语使用。
助动词
除了动词本身的变化,经常我们还会发现动词可能和其它词一起构成谓语,比如have, will, can, could, to。
这类词中,一些词用来表示不确定的语气:
He may be wrong.
这里be动词前面使用了助动词may来表达不确定的语气,此外,could, might等也有不确定的语气。
而will则是主要用于表示某种意愿和未来的事情(比如用在将来时态中),
have用于过去完成时表示已经完成的含义,不定式to do其实可以看作带有助动词的从句省略(后文进一步阐述)。
宾语和补语
看完动词,我们还需要稍微了解一下名词和形容词,这两类经常被用于宾语和补语中。
从句
现在我们有了基本句式、动词变形以及助动词补足语气,接下来让我们开启任何语言都十分重要的部分:组合。 有了句子,自然会考虑如何将小句子组合成更大的句子,在编程语言中,我们有组合子;在英语中,我们有从句。
传统语法喜欢将从句进行分类:
- 名词从句
- 副词从句
- 关系从句
这种分类是ok的,我们就按照这个分类进行讨论。考虑这样两个句子:
He said something.
He is a programmer.
如果他说的内容就是第二句,即他想告诉我们他是个程序员,那么我们可以使用从句将这两句组合起来:
He said that he is a programmer.
副词从句经常使用when, where等表达时间、地点等额外的信息修饰句子。
省略原则
自然语言往往会为了追求便捷性进行句子省略,同时显现出某种「言外之意」。 有趣的是,许许多多复杂的英语语法可以被归纳为从句省略:
- 不定式是从句中有助动词时的一种省略
- 主谓宾补是从句为SVC结构时的一种省略
- 同位语也是SVC的一种省略表达
省略的原则十分简单:
省略从句中主语与 be 动词,只保留补语部分。
Golang does have sum types, however...
@tag(programming)
Golang has no sum type!
People like to say that golang lacks sum types.
For example, in Rust we can write a simple Result type:
#![allow(unused)] fn main() { enum Result<T, E> { Ok(T), Err(E), } }
Here Result is a sum type which can only be one variant(Ok or Err) but not both.
Sum types are really useful to constraint values. In category theory, sum type is dual to product type, which is a universal type. If product types can be written as a * b, then sum types can be written as a + b.
Golang lacks direct support on sum types, but we can still simulate it:
type result[T, E any] interface {
isResult()
}
type Result[T, E any] struct {
inner result[T, E]
}
type Ok[T, E any] struct {
value T
}
type Err[T, E any] struct {
err E
}
func (Ok[T, E]) isResult() {}
func (Err[T, E]) isResult() {}
func (res Result[T, E]) Switch() result[T, E] {
return res.inner
}
To match variants:
func matching[T, E any](res Result[T, E]) {
switch r := res.Switch().(type) {
case Ok[T, E]:
_ = r.value
case Err[T, E]:
default:
}
}
However, since golang doest not have generic methods, its function is still limited(golang team is far too conservative)...
Although we can simulate Result sum type in Golang, we are still forced to use (T, error) and write if err != nil lol. What a great language!
Rewatch Code Geass
@tag(anime)
Code Geass is one of my favorite animes.

Another view of Rust's lifetime
@tag(programming) @tag(rust)
Compared with Haskell, Rust is different for its effect system and ownership system. Inside ownership system, lifetime plays an important role on borrowing and safety. Traditionally, people think about lifetime as some region of code, which is a little kind of vague. Why not try to see lifetime as a kind of memory(dependency) reference?
Lifetime as scope?
The Rust book suggests viewing lifetime as scopes. Consider a simple example:
fn main() { let r; // ---------+-- 'a // | { // | let x = 5; // -+-- 'b | r = &x; // | | } // -+ | // | println!("r: {r}"); // | } // ---------+
Since x's lifetime 'b is shorter than r's 'a, we cannot assign &x to r.
However, this reason is rather imprecise.
If we simply remove the last println! line, this code just compile fine.:
fn main() { let r; // ---------+-- 'a // | { // | let x = 5; // -+-- 'b | r = &x; // | | } // -+ | } // ---------+
Why?
Even worse, lifetime can contain holes, where it’s intermittently invalid between where it starts and where it ultimately ends. For example, let's change our previous code simply:
fn main() { let i = 42; let mut r; { let x = 5; r = &x; // -------------+-- 'r // | } // -------------+ r = &i; // -------------+-- 'r println!("r: {}", *r); // | } // -------------+
This time the code compiles. Surprise!
Why? why this code compiles fine?? If r's lifetime coprresponds to x's reference, why r can br printed outside x's scope now? There may exist holes in lifetime.
Apparently scope view is not correct. We need something better.
Lifetime as regions of code?
Rustonomicon the book suggests viewing lifetime as named regions of code.
Now our previous problems are solved, since 'r spans only its valid data flow regions and the regions can contains arbitrary holes.
Lifetime is named regions of code where the pointed data is valid.
What about lifetime constraints like 'a: 'b?
Lifetime subtyping
Subtyping is really just a spectial relation just as other traits can represent. The only subtyping in rust is lifetime subtyping.
if
'boutlives'a, then'b: 'aand&'b Tis a subtype of&'a T.
Since &'b T is a subtype of &'a T, we can assign any &'b T to &'a T.
For example(again from the rust book):
#![allow(unused)] fn main() { fn longer<'a>(s1: &'a str, s2: &'a str) -> &'a str { if s1.len() > s2.len() { s1 } else { s2 } } }
Actually, this code cannot compile without lifetime subtyping. It's equivalent to this code:
#![allow(unused)] fn main() { fn longer<'a, 'b, 'c>(s1: &'a str, s2: &'b str) -> &'c str where 'a: 'c, 'b: 'c, { if s1.len() > s2.len() { s1 } else { s2 } } }
Automatic subtyping is only a fancy and convenient way to expression this relationship.
Lifetime as memory references
If you know category theory, you may heard of duality. Just like category theory, the code region view also has its DUAL view:
A lifetime refers to some memory or other resources and constraint
'a: 'bcan also be read'arefers to a subset of'bor, if you like,'ain'b.
In this dual view, if 'a outlives 'b, 'b contains more resources than 'a does.
I find this view is somehow complement to the region view.
Let's demonstrate this view with the following code:
#![allow(unused)] fn main() { fn use_longer() { let a: &str = "a"; // 'a let b: &str = "b"; // 'b let c: &str = "c"; // 'c let d = longer(a, b); // 'd let d = longer(c, d); // 'e } }
'e -> {
'd -> {
'a,
'b,
},
'c,
}
where arrow -> means point to some resource and {} means union.
From this graph, we can easily conclude:
'a: 'd
'b: 'd
'd: 'e
'c: 'e
'a: 'e
'b: 'e
The two sides of programming languages
@tag(programming)
Some people ask for programming languages worth learning. I think almost all common languages worth a try, but I personally prefer two sides of programming languages. You can imagine that there exists a balance whose left side represents machine and right represents abstraction.
The Abstraction side
The abstraction side is the lost side in computer science classes. To be precise, the abstraction is mainly about Programming Language Theory(PLT) and Math.
I still remember how enjoyful I was when I first the book SICP. It uses Scheme the language to show you how programs are constructed from ground. But Scheme lacks the world of static typing. Haskell uses a different way to express types and side-effects. It also introduce Category theory into programming, especially for Monads and Functors. You can even learn more computaional models with more powerful typing system. The Haskell's way of programming can lead you to the world of dependent types where types can depend on values. I like the way Lean4 uses to construct math proof and provide higher-level categorical structures.
The Machine side
The machine side is the traditional side which almost all CS lessons focus on. I think this side is so famous that you must known better than me. Personally, I love C and Rust with some assembly codes.
Together
The Rust language puts two sides together! I love it so much.
My progamming key bindings
@tag(programming)
I like the idea of editing of VIM, but I still think this is not the best. Some keys of vscode, emacs and particularly Kakoune ans helix are modern.
General idea
Action follows selection.
Major modes
Minor modes
Keys
Normal mode
Movement
| Key | Desc. |
|---|---|
h, Left | Move left |
j, Down | Move down |
k, Up | Move up |
l, Right | Move right |
w | Move next word start |
b | Move previous word start |
e | Move next word end |
f | Find next char |
t | Find 'till next char |
F | Find previous char |
T | Find 'till previous char |
Ctrl-b, PageUp | Move page up |
Ctrl-f, PageDown | Move page down |
Ctrl-u | Move cursor and page half page up |
Ctrl-d | Move cursor and page half page down |
0 | Jump to the start of the line |
^ | Move to the first non-blank character of the line |
$ | Move cursor line end |
G | Go to the last line of the document |
Ctrl-o, Ctrl-- | Go previous cursor location |
Ctrl-i | Go next cursor location |
Changes
| Key | Desc. |
|---|---|
r | Replace with a character |
R | Replace with yanked text |
~ | Switch case of the selected text |
i | Insert before selection |
a | Insert after selection (append) |
I | Insert at the start of the line |
A | Insert at the end of the line |
o | Open new line below selection |
O | Open new line above selection |
u | Undo change |
U | Redo change |
y | Yank selection |
p | Paste after selection |
P | Paste before selection |
"<reg> | Select a register to yank to or paste from |
> | Indent selection |
< | Unindent selection |
= | Format selection (LSP) |
d | Delete selection |
c | Change selection (delete and enter insert mode) |
Q | Start/stop macro recording to the selected register |
q | Play back a recorded macro from the selected register |
Alt-Up | Move line upward |
Alt-Down | Move line downward |
Selection
| Key | Desc. |
|---|---|
s | Select all regex matches inside selections |
C | Copy selection onto the next line (Add cursor below) |
, | Keep only the primary selection |
%, Cmd-a | Select entire file |
x | Select current line, if already selected, extend to next line |
Searching
| Key | Desc. |
|---|---|
/ | Search for regex pattern |
? | Search for previous pattern |
n | Select next search match |
N | Select previous search match |
* | Use current selection as the search pattern |
File
| Key | Desc. |
|---|---|
Cmd-s | Save current file |
Cmd-n | Open new buffer |
Insert mode
Press i in normal mode
| Key | Desc. |
|---|---|
Escape | Switch to normal mode |
Ctrl-a | Goto line begin |
Ctrl-e | Goto line end |
Ctrl-d, Delete | Delete next char |
Ctrl-j, Enter | Insert new line |
Ctrl-x | Autocomplete |
Alt-Delete | Delete word backward |
Ctrl-u | Delete to start of line |
Ctrl-k | Delete to end of line |
Picker mode
| Key | Desc. |
|---|---|
Shift-Tab, Up, Ctrl-p | Previous entry |
Tab, Down, Ctrl-n | Next entry |
PageUp, Ctrl-u | Page up |
PageDown, Ctrl-d | Page down |
Home | Go to first entry |
End | Go to last entry |
Enter | Open selected |
Escape, Ctrl-c | Close picker |
Prompt mode
| Key | Desc. |
|---|---|
Escape, Ctrl-c | Close prompt |
Alt-b, Ctrl-Left | Backward a word |
Ctrl-f, Right | Forward a char |
Ctrl-b, Left | Backward a char |
Alt-f, Ctrl-Right | Forward a word |
Ctrl-e, End | Move prompt end |
Ctrl-a, Home | Move prompt start |
Ctrl-w, Alt-Backspace, Ctrl-Backspace | Delete previous word |
Alt-d, Alt-Delete, Ctrl-Delete | Delete next word |
Ctrl-u | Delete to start of line |
Ctrl-k | Delete to end of line |
Backspace, Ctrl-h, Shift-Backspace | Delete previous char |
Delete, Ctrl-d | Delete next char |
Ctrl-p, Up | Select previous history |
Ctrl-n, Down | Select next history |
Tab | Select next completion item |
Enter | Open selected |
Popup mode
| Key | Desc. |
|---|---|
Ctrl-u | Scroll up |
Ctrl-d | Scroll down |
View mode
Press z in normal mode
| Key | Desc. |
|---|---|
z, c | Vertically center the line |
t | Align the line to the top of the screen |
b | Align the line to the bottom of the screen |
m, z | Align the line to the middle of the screen |
j, down | Scroll the view downwards |
k, up | Scroll the view upwards |
Ctrl-f, PageDown | Move page down |
Ctrl-b, PageUp | Move page up |
Ctrl-u | Move cursor and page half page up |
Ctrl-d | Move cursor and page half page down |
Select mode
Press v in normal mode
| Key | Desc. |
|---|---|
; | Cancel selected region |
Goto mode
Press g in normal mode
| Key | Desc. |
|---|---|
g | Go to line number |
e | Go to the end of the file |
f | Go to files in the selections |
h | Go to the start of the line |
l | Go to the end of the line |
s | Go to first non-whitespace character of the line |
t | Go to the top of the screen |
c | Go to the middle of the screen |
b | Go to the bottom of the screen |
d | Go to definition (LSP) |
y | Go to type definition (LSP) |
r | Go to references (LSP) |
i | Go to implementation (LSP) |
a | Go to the last accessed/alternate file |
m | Go to the last modified/alternate file |
n | Go to next buffer |
p | Go to previous buffer |
w | Show labels at each word and select the word that belongs to the entered labels |
Match mode
Press m in normal mode
| Key | Desc. |
|---|---|
m | Goto matching bracket |
s <char> | Surround current selection with |
r <from><to> | Replace surround character |
d <char> | Delete surround character |
a <object> | Select around textobject |
i <object> | Select inside textobject |
Window mode
Press Ctrl-w in normal mode
| Key | Desc. |
|---|---|
w, Ctrl-w | Switch to next window |
v, Ctrl-v | Vertical right split |
s, Ctrl-s | Horizontal bottom split |
f | Go to files in the selections in horizontal splits |
F | Go to files in the selections in vertical splits |
h, Ctrl-h, Left | Move to left split |
j, Ctrl-j, Down | Move to split below |
k, Ctrl-k, Up | Move to split above |
l, Ctrl-l, Right | Move to right split |
q, Ctrl-q | Close current window |
o, Ctrl-o | Only keep the current window, closing all the others |
H | Swap window to the left |
J | Swap window downwards |
K | Swap window upwards |
L | Swap window to the right |
Space mode
Press Space in normal mode
| Key | Desc. |
|---|---|
f | Open file picker |
F | Open file picker at current working directory |
b | Open buffer picker |
j | Open jumplist picker |
k | Show documentation for item under cursor in a popup (LSP) |
s | Open document symbol picker (LSP) |
S | Open workspace symbol picker (LSP) |
d | Open document diagnostics picker (LSP) |
D | Open workspace diagnostics picker (LSP) |
r | Rename symbol (LSP) |
a | Apply code action (LSP) |
h | Select symbol references (LSP) |
c | Comment/uncomment selections |
/ | Global search in workspace folder |
? | Open command palette |
Unimpaired
| Key | Desc. |
|---|---|
]d | Go to next diagnostic (LSP) |
[d | Go to previous diagnostic (LSP) |
]D | Go to last diagnostic in document (LSP) |
[D | Go to first diagnostic in document (LSP) |
]f | Go to next function (TS) |
[f | Go to previous function (TS) |
]t | Go to next type definition (TS) |
[t | Go to previous type definition (TS) |
]a | Go to next argument/parameter (TS) |
[a | Go to previous argument/parameter (TS) |
]c | Go to next comment (TS) |
[c | Go to previous comment (TS) |
]T | Go to next test (TS) |
[T | Go to previous test (TS) |
]p | Go to next paragraph |
[p | Go to previous paragraph |
Editors
I current use vscode for its light-weight and extensions. I use the extension Dance - Helix Alpha and EasyMotion to simulate Helix's key bindings.
Also, I add some key bindings:
// Place your key bindings in this file to override the defaultsauto[]
[
{
"key": "Escape",
"command": "dance.modes.set.normal",
"when": "editorTextFocus"
},
{
"key": "ctrl+w",
"command": "vscode-easymotion.jumpToWord",
"when": "editorTextFocus && dance.mode == 'insert'"
},
{
"key": "=",
"command": "editor.action.formatDocument",
"when": "editorTextFocus && dance.mode == 'normal'"
},
{
"key": "Ctrl+[",
"command": "workbench.action.navigateBack",
"when": "editorTextFocus && dance.mode == 'normal'"
},
{
"key": "Ctrl+]",
"command": "workbench.action.navigateForward",
"when": "editorTextFocus && dance.mode == 'normal'"
}
]
When using Vscode Vim plugin, I include the following settings:
{
"vim.easymotion": true,
"vim.incsearch": true,
"vim.useSystemClipboard": true,
"vim.useCtrlKeys": true,
"vim.hlsearch": true,
"vim.insertModeKeyBindings": [
{
"before": ["j", "j"],
"after": ["<Esc>"]
},
{
"before": ["<C-j>"],
"commands": [
"cursorDown"
]
},
{
"before": ["C-k"],
"commands": ["cursorUp"]
},
{
"before": ["C-h"],
"commands": ["cursorLeft"]
},
{
"before": ["<C-l>"],
"commands": ["cursorRight"]
}
],
"vim.normalModeKeyBindingsNonRecursive": [
{
"before": ["<leader>", "d"],
"after": ["d", "d"]
},
{
"before": ["<C-n>"],
"commands": [":nohl"]
},
{
"before": ["K"],
"commands": ["lineBreakInsert"],
"silent": true
}
],
"vim.leader": "<space>",
"vim.handleKeys": {
"<C-a>": false,
"<C-e>": false,
"<C-f>": false
},
"vim.smartRelativeLine": true,
"vim.cursorStylePerMode.insert": "line-thin",
"vim.cursorStylePerMode.normal": "block",
"vim.normalModeKeyBindings": [
{
"before" : ["<leader>","w"],
"commands" : [
"workbench.action.switchWindow",
]
},
{
"before" : ["<leader>","s"],
"commands" : [
"workbench.action.showAllSymbols",
]
},
{
"before" : ["<leader>","f"],
"commands" : [
"workbench.action.quickOpen",
]
},
{
"before" : ["<leader>","r"],
"commands" : [
"workbench.action.openRecent",
]
},
{
"before" : ["<leader>","a"],
"commands" : [
"editor.action.quickFix",
]
},
{
"before": ["<leader>", "p"],
"commands": [
"workbench.action.showCommands"
]
},
{
"before": ["g", "r"],
"commands": [
"editor.action.goToReferences"
]
},
{
"before": ["g", "i"],
"commands": [
"editor.action.goToImplementation"
]
}
],
}
Polymorphism in Rust
@tag(programming) @tag(rust)
Every language has polymorphism functions. Some utilize dynamic interfaces, some invent generics and typeclass to overload behavories.
Rust has both.
In Rust, we have type parameters and traits.
Rust really prefer generics over existential types. If one want to be Debug, just "generic" it:
#![allow(unused)] fn main() { fn use_debug<A: fmt::Debug>(a: A); }
We also have associated types, where clauses, impl types, etc. These all lift our type to polymorphism. However, there still exists two kinds of polymorphism which are somewhat hard to achieve in Rust now.
Effect polymorphism
It's somewhat hard to explain what effect is because side-effects is nearly everywhere and we can't live without it! Effects are everything except for function input/output. Think about errors, asynchrony, uncertainty. Think about it and try to guess what they correspond to in out daily programming.
Yes, they are Result<_>, Future<Output=_> and various kinds of containers. Now suppose you want to write some fn which performs some unknown effect:
#![allow(unused)] fn main() { fn func<F>(x: i32) -> F<i32>; }
Congratulations! we discovers Higher-Kinded Types(HKT). But you may also have noticed that this is not enough since Future is a trait and we have no way of abstract traits. Apparently Rust does not like Monads. In Rust, abstracting effects is really really hard right now. If you want to write one API for both sync and async codes, I just suggest you to write two separate traits.
Ownership polymorphism
Another one is ownership, which is also ubiquitous in Rust. Suppose you want write some AST like:
#![allow(unused)] fn main() { enum Expr { Var(String), Call { f: Expr, args: Vec<Expr> }, Lambda { args: Vec<Expr>, body: Expr } } }
Apparently this does not compile since Expr is not Sized.
We have to add some ownership for every recurrent position. For example:
#![allow(unused)] fn main() { enum Expr { //... Call { f: Box<Expr>, /*..*/ } //... } }
However, Box has exclusive ownership, what about Rc or even Arc?
You can just abstract the whole recurrent type as:
#![allow(unused)] fn main() { enum Expr<This> { Call { f: This, args: Vec<This> } } type Exprs = Expr<Rc<Expr<???>>> }
Expr is a fixpoint! This way we now have infinite type.
How about just abstract HKT?
#![allow(unused)] fn main() { pub trait Kind { type F<T>; } enum Expr<K: Kind> { Call { f: K::F<Self>, args: Vec<K::F<Self>> }, } }
HKTs are really useful on abstracting * -> * types!
I believe in the future, we can have effect polymorphism with Coroutine one-shot algebraic effects and ownership polymorphism with GAT and impl type alias.
Relaxed ordering and visibility
@tag(programming)
I'm really curious that whether the relaxed memory ordering can ensure to see the last recent value in the total modification order. It appears that the C++ memory model alone is not enough.
The C++ memory model only states that
Implementations should make atomic stores visible to atomic loads within a reasonable amount of time.
which means in the code
std::atomic<int> g{0};
// thread 1
g.store(42);
// thread 2
int a = g.load();
// do stuff with a
int b = g.load();
if thread 1 has executed the storing, thread 2 is not guaranteed to load 42 immediately.
However, C++ standard does ensure the visibility of RMW(Read-Modify-Write) operations as the standard says:
Atomic read-modify-write operations shall always read the last value (in the modification order) written before the write associated with the read-modify-write operation.
which means you don't need to worry about operations like fetch_xx and compare_exchange.
Golang is terrible as a general purpose language
@tag(programming)
Golang is terrible at several things:
-
Try to mix up defaults, empty value, empty slice, null pointer and optional value. Function callers have to check all these things to avoid PANIC! Also comparing nil values with poor type inference is really dirty.
-
Try to mix up sum type and product type. Golang likes to simulate sum type with product types (e.g., return extra error), which is error-prone for several things:
- Cannot ensure exclusive variant. You may receive both a return value and non-nil err.
- You may also try to simulate sum type with interfaces, but interface is implicit and not sealed.
-
Try to mix up dynamic and compile-time polymorphism. Many APIs have to use
interface{}and methods on receivers cannot have generic parameters. -
Try to mix up SHOULD implement and HAPPEN TO implement. Due to poor expressiveness of golang's type system, you may happens to implement some interfaces with wrong semantic.
-
Try to mix up directory hierarchy and module system. You have to
mkdirto create inner modules.
Golang pros:
- Fast development with bugs.
- Fast compiling time with little static check.
H1
这群在连云港过冬的蛎鹬本来依赖两个因放水而露出底部的鱼塘作为高潮栖息地,但是前段时间鱼塘又开始蓄水,让它们失去了合适的高潮地,潮水上涨时候只能像这样挤在鱼塘边的土质堤坝上,休息环境更差而且容易受人惊扰,实在是很可怜
H2
H3
- 1
- 2
font
testing: code
testing: italic
testing: bold
mathjax
\( \int x dx = \frac{x^2}{2} + C \)
\[ \mu = \frac{1}{N} \sum_{i=0} x_i \]
katex
testing: inline formula:
testing: block formula:
code
#include __FILE__
template <typename T, class C, int R>
using T = C<R>;
static inline register void main(){
auto f = main();
int a = (long) (void*) &f;
f(a);
return 1;
}